
As one of two summer 2017-18 student interns for the Kōrero Māori project with Dragonfly Data Science, Te Hiku Media and Te Pūnaha Matatini, we were assigned to help collect corpus of te reo Māori text that would be used to train the written language model component of a te reo Māori computer natural language processing engine. When ready, the natural language processor will be used as the base for making software like Apple’s artificially intelligent ‘Siri’, that will be capable of understanding te reo Māori.
One text source in particular was identified that is publicly available online and known to contain te reo Māori – that is the New Zealand Parliamentary Debates as recorded in the Hansard reports.
The written record of Parliamentary Debates (Hansard) make up over 700 volumes of text that span from 1854 to the present day, and daily reports continue to be published online within a fews hours of each new thing spoken in Parliament.
Working through the Hansard
A variety of challenges were encountered while programming an algorithm that could successfully sort through the text in all the volumes, accounting for a variety of text structures, and detecting and extracting te reo Māori.
Hansard characteristics:
- Hansard volumes prior to 1867 are assembled from newspaper publications and the like – the Hansard reporters first began their work in 1867.
- Prior to volume 410 (1977), speeches were not always directly quoted and were often written in a narrative style. It is a possibility that at times te reo was spoken but only recorded as a narrative in english. From volume 410 onwards, all speeches are directly quoted.
- Prior to volume 483 (1987), the volumes are published using non-digital means. Digital text has been generated from optical character recognition of scans – OCR from the earlier volumes is not the best. From volume 483 (1987) onwards the debates are published using computer word processing software.
- In 1994 the Hansard reports begin to use macronised vowels for te reo Māori words.
- From volume 606 (2003) onwards, the daily Hansard reports are available online as HTML formatted web pages.
In the end, the programme extracts segments of speech that have a high percentage of Māori words. It also counts all the Māori, non-Māori and ambiguous (e.g. ‘he’, ‘to’, ‘a’) words that are spoken within each day of debates.
Across the 700+ volumes, the programme has sorted through over 420 million words to detect about 7400 speech segments that are at least 50% te reo and have a combined total of about 390,000 Māori words.
History of te reo in Parliament
Several interesting discoveries were made after examining the result and making a graph (see figure below):
- Up until the 1980s the proportion of te reo Māori speech in Parliament was barely anything – less than 0.1% for more than 130 years. However over the last 2-3 decades the growth trend in the percentage of te reo spoken in Parliament is very remarkable, even reaching as high as 2% in a year.
- We found that Māori words make up about 0.2-0.4% of what people say in Parliament on average if they aren’t speaking in te reo Māori – most probably common words like names.
- A cluster of te reo speeches around the 1940s.
- Several MP speeches that include other Polynesian languages are counted to contain about 50% – 70% “Māori” words – this is due to similarity between languages and alphabets.
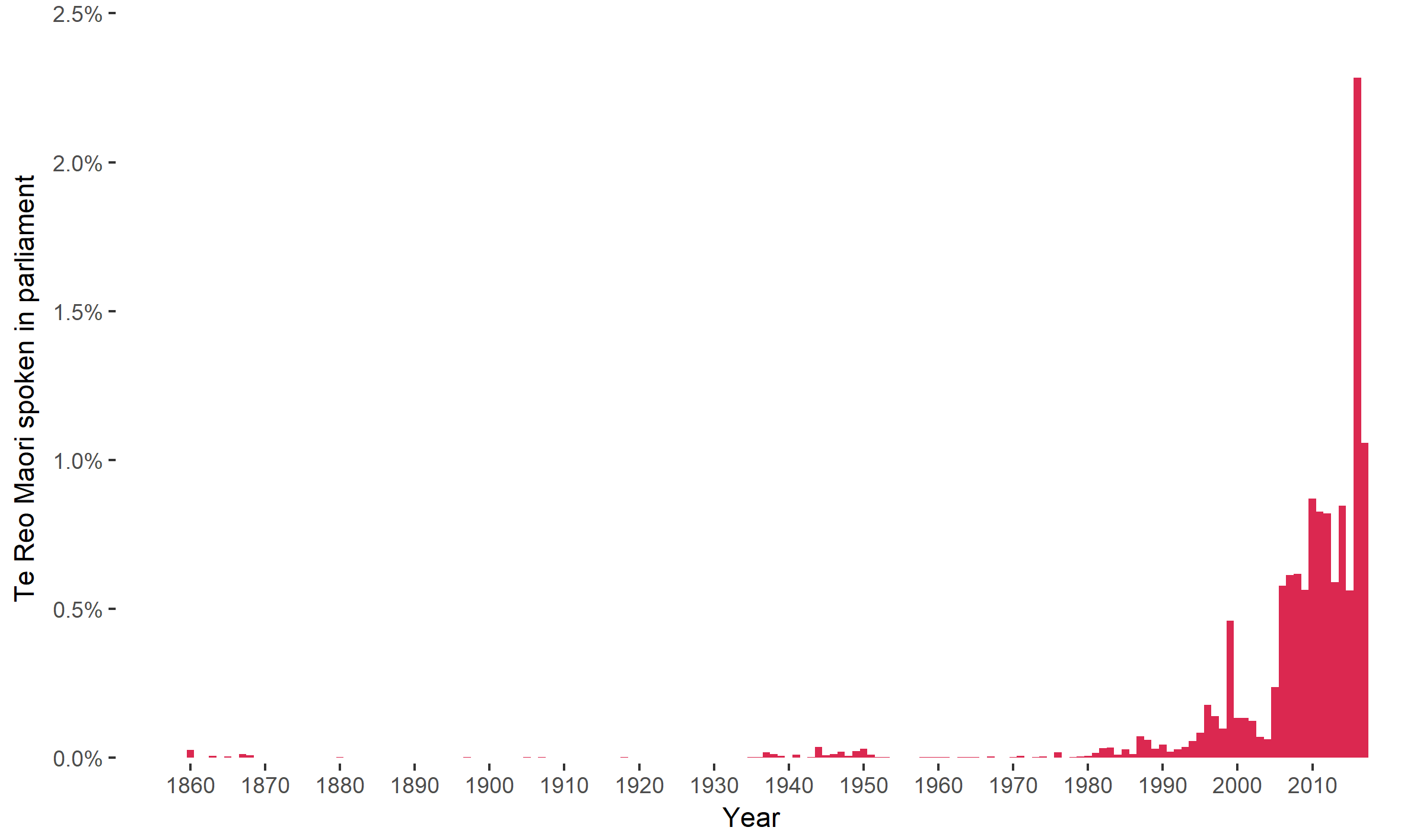
Figure courtesy of Te Hiku Media.
Interpretation of the growth trend
Viewing Parliament and the New Zealand House of Representatives in the context of an institution that endeavours to represent the whole of Aotearoa New Zealand, the kinds of social interactions that occur within Parliament can also be interpreted as a general indicator, as an approximation, and as the emergent result of the many kinds of cultural interactions and social dynamics that are happening on the ground across broader New Zealand society as a whole. In this sense, the amount of te reo spoken in Parliament, or any language for that matter, reflects the current position that language has in society. The growth in te reo Māori used in Parliament appears to parallel the time period from when Te Kohanga Reo and Te Reo Māori revitalisation movement began, as well as from the time when the process of settling Tiriti grievances began.
What next?
Over the summer we interns managed to aggregate several thousand te reo sentences combined, including from sources such as the historical Māori newspapers. However, over 100,000 sentences are required to train a good language model, so there is still a lot more corpus gathering to be done.
The program scripted for the Hansard debates can be run again and again as new debates are published to continue growing the corpus of te reo Māori. The script can also be adapted and reworked to sort through other text sources that consist of paragraphs and sentences, particularly bilingual text.
In addition, with a little more work on this particular code we can start to keep account of:
- The percentage of Māori spoken by each Member of Parliament over time
- The percentage of Māori spoken by each Party over time
- Count other Pacific/Polynesian languages when spoken in Parliament
Closing thoughts
The sudden upswing in te reo in Parliament in the last 20 – 30 years is astounding. From practically 0 to 1-2% in a couple of decades, imagine what it could look like in years to come:
- When the percentage of te reo spoken in Parliament begins to match the size of the Māori population (~15%).
- When the percentage of te reo spoken in Parliament approaches 50%, and the nation is almost 100% Māori bilingual.
No doubt, machines that have learnt to kōrero Māori will play an important part in such developments as we continue the journey onward into the technological future. Performing this mahi as a tauira intern for the Kōrero Māori project has been a great learning experience. I have been able to learn from professionals and sharpen my programming and data processing skills all for this deeply meaningful kaupapa with compelling implications for the digital future of languages indigenous to Te Moana-nui-a-Kiwa, and I am very humbled to have had the opportunity to contribute to its development.
Author
William Asiata is a BSc Mathematics graduate from the University of Canterbury and a current Master of Information Technology student at the University of Auckland. William is passionate about the development and application of social choice algorithms to the construction of social networking systems, and how this will impact the future of civic technologies. William is also interested in the social evolution of peoples across Oceania.