
I wrote this algorithm to classify people by gender, but one of the biggest things I learned was how machine learning can reinforce racism and perform poorly on ethnic minorities.
Machine learning – or programs that are able to learn from and improve on past experience and data – is often accused of reinforcing human biases such as racism and sexism. However, it can be a bit unclear how exactly this happens.
How does an automatic soap dispenser fail to recognize black people’s hands? How does image recognition software come to classify people in kitchens as women, regardless of their actual gender? How does artificial intelligence that seeks to predict criminal recidivism produce results that are consistently biased against black people?
This walk-through hopes to give you a bit of an insight into one example of racism in machine learning, and how this comes to be.
The algorithm will be used as part of research into gender equity in STEM fields in New Zealand. A lot of information about who works in certain research centres or who graduated from university is publicly available online (for example, here are university records from NZ between 1870 and 1961), but it doesn’t explicitly include their gender. While a person reading the information can usually guess their gender quite easily and with a high degree of accuracy, it’s obviously very impractical to read and classify thousands or hundreds of thousands of observations. This is where this algorithm hopes to simplify and speed up the process of identifying women in STEM fields.
Training and testing data: Selecting appropriate data
Getting good data for the training and test sets is a really important part of machine learning. Your model is only as good as the data you train and test it on, so getting this right is key.
The starting point of my dataset is the 100 most common names for boys and girls born in New Zealand in each year, going back to 1954. One major drawback of this dataset is that it only includes people born in New Zealand, not those that emigrated here. This means the dataset is almost exclusively made up of Anglo-Saxon names, and does not reflect New Zealand’s large Asian and Pacific populations.
🎉 New #data alert! 🎉
We’ve just updated our figures on a topic that’s always popular – #baby names 👶🏽
Charlotte and Oliver topped the 2017 charts, but we’re sure you’ll spot plenty of other familiar names. Know anyone with a name that made the top 50? pic.twitter.com/A1eHH4kGq5
— Figure.NZ (@FigureNZ) January 30, 2018
It also doesn’t include any Māori names, presumably because the Māori population isn’t large enough for these names to make the top 100 list. I’ve tried to remedy this by adding the top 20 Māori names for boys and girls from several years to the dataset. However, 91% of the training dataset is still made up of Anglo-Saxon names, while only 9% is made up of Māori names.
These biases in the training dataset mean that the model is likely to recognize the patterns that indicate gender in Anglo-Saxon names, while not picking up on patterns that indicate gender in the names of other cultures. The same biases in the testing dataset mean that the accuracy of the model probably only applies to Anglo-Saxon names, and that it may do much worse on names of other nationalities.
Selecting useful features for the algorithm
It’s important to consider what features would be most useful in predicting the desired classes. I started off by using the last letter of each name to predict gender. Most Anglo-Saxon names for men end with a consonant, while most Anglo-Saxon names for women end with a vowel.
There are also some pairs of letters that are more common for one gender than the other. For example, the last letter ‘n’ is indicative of a male name (e.g. Brian, Aidan, John), but the suffix ‘yn’ is indicative of a female name (eg. Robyn, Jasmyn). Because of this, using both the last letter of each name and the suffix as features results in higher accuracy than just using the final letter. This gave me an accuracy of about 73% on a testing dataset that includes both Anglo-Saxon and Māori names.
This overall accuracy is lower than it would have been on a testing dataset made up of only Anglo-Saxon names because these features don’t perform as well with names of other origins. In a New Zealand context, this causes the most problems with Māori names. Most Māori names end in vowels, regardless of gender (examples of male Māori names include Tane and Nikau, while female Māori names include Aroha and Kaia). This means this particular feature doesn’t do a very good job with names of Māori origin.
The same problem would likely apply to other ethnicities, too. For example, Japanese, Chinese, Vietnamese, Italian and Hispanic names all often end in vowels, regardless of gender.
Imbalanced classes and the problems they cause
Imbalanced classes, or classes that are very different in their size, can also create problems for machine learning algorithms. In this case, ethnicity is an imbalanced class that is likely to influence people’s names. In the 2013 census, 74% of New Zealanders identified as European, 15% as Māori, 12% as Asian and 7% as Pacific. (Note that Statistics New Zealand allows you to identify with more than one ethnicity, therefore these numbers don’t add up to 100%).
Imbalanced classes often result in high accuracy within the majority class (in this case, European) and low accuracy within the minority classes (Māori, Asian and Pacific). This particular algorithm has an overall accuracy of about 73%. The accuracy within Māori names is about 69%, while the accuracy within European names is 75%.
The class imbalances in the data explain why the overall accuracy may not be a very good way of assessing whether the algorithm is working well. As well as checking the accuracy within each subgroup, it can be a good idea to look at precision and recall for more information on where the algorithm is doing well and where it’s doing poorly.
Precision tells us how much of a classified group actually belongs to that group. In this case, for example, precision of female names is the percentage of names classified as female that are actually female. It is calculated by dividing the number of true positive (number of women classified as female) by all positives (number of women and men classified as female).
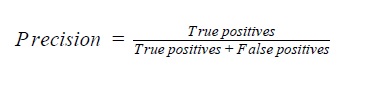
Recall is the percentage of a particular group that has been classified as belonging to that group. For example, recall of male names is the percentage of male names that have been classified as male. Recall is calculated by dividing the number of true positives (number of men classified as male) by the number of true positives and false negatives (number of men classified as female).

The tables below show the precision, recall and a couple of other metrics on how well the algorithm is doing. The differences between the overall table and the tables by ethnicity show that it’s likely that this algorithm is systematically worse with non Anglo-Saxon names, specifically Māori names in this instance.
Overall:
| precision | recall | F1 score | support | |
| F | 0.77 | 0.76 | 0.77 | 274 |
| M | 0.71 | 0.72 | 0.72 | 226 |
| avg/total | 0.74 | 0.74 | 0.4 | 500 |
For Māori names only:
| precision | recall | F1 score | support | |
| F | 0.75 | 0.88 | 0.81 | 17 |
| M | 0.33 | 0.17 | 0.22 | 6 |
| avg/total | 0.64 | 0.70 | 0.66 | 23 |
Here we can see that both precision and recall is very low for male Māori names. This means that only a small percentage of the names classified as being male actually are male (low precision) and an even smaller percentage of male Māori names have been classified as being male (low recall).
This is probably because most Māori names end in vowels, regardless of their gender. The algorithm does alright on female Māori names, because it has seen many instances of female names ending in vowels before. But it hasn’t seen many male names ending in vowels, so it fails to classify most of these names correctly.
For European names only:
| precision | recall | F1 score | support | |
| F | 0.82 | 0.72 | 0.77 | 140 |
| M | 0.7 | 0.81 | 0.75 | 115 |
| avg/total | 0.77 | 0.77 | 0.77 | 255 |
Because machine learning algorithms with imbalanced classes usually do worse in the smaller classes, they can further marginalise minority groups by routinely misclassifying them or failing to take into account patterns that are unique to the smaller group. In this example, this is likely to be the case with ethnic minorities.
It seems that this algorithm is likely to really only do a good job on Anglo-Saxon names. This limits the situations in which it would be appropriate to use it, and risks reinforcing Eurocentricity and a focus on whiteness.
This example shows how difficulties in getting hold of representative datasets, selecting features and unbalanced classes can cause algorithms to perform poorly on minority groups. These are only a couple of the many ways machine learning can contribute to the marginalisation of minorities, and it’s important to consider how this might happen in the particular algorithm you’re working on.
The consequences of bias in machine learning can range from the irritation of not being able to get soap out of an automatic dispenser, to the devastation of being given a longer prison sentence. As these algorithms become more and more ubiquitous, it is essential that we consider these consequences in the design and application of machine learning.
See this paper for a more detailed look at how imbalanced classes affect machine learning algorithms.
Author
Emma Vitz is a recent Statistics & Psychology graduate of Victoria University who is starting a new role at an actuarial consulting company in Auckland. Emma enjoys applying data science techniques to all kinds of problems, especially those involving people and the way they think.